 江哥架构师笔记
江哥架构师笔记gin框架路由详解
gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
Radix Tree
基数树(Radix Tree)又称为PAT位树(Patricia Trie or crit bit tree),是一种更节省空间的前缀树(Trie Tree)。对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。下图为一个基数树示例:
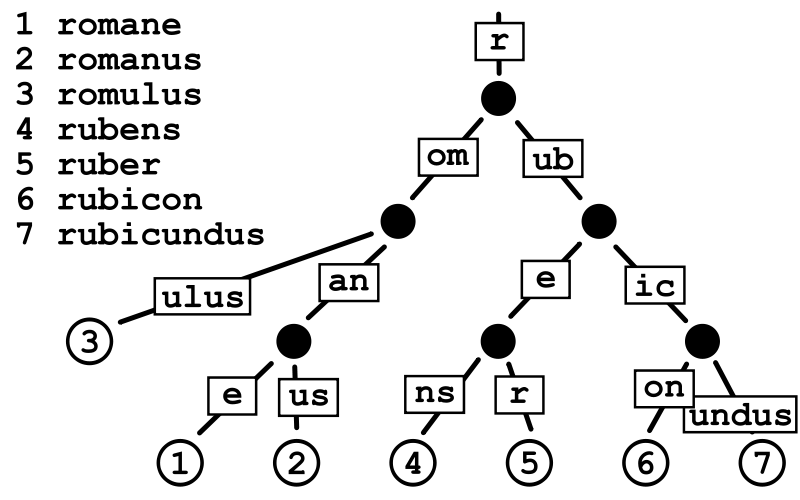
Radix Tree可以被认为是一棵简洁版的前缀树。我们注册路由的过程就是构造前缀树的过程,具有公共前缀的节点也共享一个公共父节点。假设我们现在注册有以下路由信息:
r := gin.Default()
r.GET("/", func1)
r.GET("/search/", func2)
r.GET("/support/", func3)
r.GET("/blog/", func4)
r.GET("/blog/:post/", func5)
r.GET("/about-us/", func6)
r.GET("/about-us/team/", func7)
r.GET("/contact/", func8)
那么我们会得到一个GET方法对应的路由树,具体结构如下:
Priority Path Handle 9 \ *<1> 3 ├s nil 2 |├earch\ *<2> 1 |└upport\ *<3> 2 ├blog\ *<4> 1 | └:post nil 1 | └\ *<5> 2 ├about-us\ *<6> 1 | └team\ *<7> 1 └contact\ *<8>
上面最右边那一列每个*<数字>表示Handle处理函数的内存地址(一个指针)。从根节点遍历到叶子节点我们就能得到完整的路由表。
例如:blog/:post其中:post只是实际文章名称的占位符(参数)。与hash-maps不同,这种树结构还允许我们使用像:post参数这种动态部分,因为我们实际上是根据路由模式进行匹配,而不仅仅是比较哈希值。
由于URL路径具有层次结构,并且只使用有限的一组字符(字节值),所以很可能有许多常见的前缀。这使我们可以很容易地将路由简化为更小的问题。此外,路由器为每种请求方法管理一棵单独的树。一方面,它比在每个节点中都保存一个method-> handle map更加节省空间,它还使我们甚至可以在开始在前缀树中查找之前大大减少路由问题。
为了获得更好的可伸缩性,每个树级别上的子节点都按Priority(优先级)排序,其中优先级(最左列)就是在子节点(子节点、子子节点等等)中注册的句柄的数量。这样做有两个好处:
-
首先优先匹配被大多数路由路径包含的节点。这样可以让尽可能多的路由快速被定位。
-
类似于成本补偿。最长的路径可以被优先匹配,补偿体现在最长的路径需要花费更长的时间来定位,如果最长路径的节点能被优先匹配(即每次拿子节点都命中),那么路由匹配所花的时间不一定比短路径的路由长。下面展示了节点(每个
-可以看做一个节点)匹配的路径:从左到右,从上到下。
├------------ ├--------- ├----- ├---- ├-- ├-- └-
路由树节点
路由树是由一个个节点构成的,gin框架路由树的节点由node结构体表示,它有以下字段:
// tree.go
type node struct {
// 节点路径,比如上面的s,earch,和upport
path string
// 和children字段对应, 保存的是分裂的分支的第一个字符
// 例如search和support, 那么s节点的indices对应的"eu"
// 代表有两个分支, 分支的首字母分别是e和u
indices string
// 儿子节点
children []*node
// 处理函数链条(切片)
handlers HandlersChain
// 优先级,子节点、子子节点等注册的handler数量
priority uint32
// 节点类型,包括static, root, param, catchAll
// static: 静态节点(默认),比如上面的s,earch等节点
// root: 树的根节点
// catchAll: 有*匹配的节点
// param: 参数节点
nType nodeType
// 路径上最大参数个数
maxParams uint8
// 节点是否是参数节点,比如上面的:post
wildChild bool
// 完整路径
fullPath string
}
请求方法树
在gin的路由中,每一个HTTP Method(GET、POST、PUT、DELETE…)都对应了一棵 radix tree,我们注册路由的时候会调用下面的addRoute函数:
// gin.go
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
// ...
// 获取请求方法对应的树
root := engine.trees.get(method)
if root == nil {
// 如果没有就创建一个
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
}
从上面的代码中我们可以看到在注册路由的时候都是先根据请求方法获取对应的树,也就是gin框架会为每一个请求方法创建一棵对应的树。只不过需要注意到一个细节是gin框架中保存请求方法对应树关系并不是使用的map而是使用的切片,engine.trees的类型是methodTrees,其定义如下:
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree // slice
而获取请求方法对应树的get方法定义如下:
func (trees methodTrees) get(method string) *node {
for _, tree := range trees {
if tree.method == method {
return tree.root
}
}
return nil
}
为什么使用切片而不是map来存储请求方法->树的结构呢?我猜是出于节省内存的考虑吧,毕竟HTTP请求方法的数量是固定的,而且常用的就那几种,所以即使使用切片存储查询起来效率也足够了。顺着这个思路,我们可以看一下gin框架中engine的初始化方法中,确实对tress字段做了一次内存申请:
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
// ...
// 初始化容量为9的切片(HTTP1.1请求方法共9种)
trees: make(methodTrees, 0, 9),
// ...
}
engine.RouterGroup.engine = engine
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
注册路由
注册路由的逻辑主要有addRoute函数和insertChild方法。
addRoute
// tree.go
// addRoute 将具有给定句柄的节点添加到路径中。
// 不是并发安全的
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
numParams := countParams(path) // 数一下参数个数
// 空树就直接插入当前节点
if len(n.path) == 0 && len(n.children) == 0 {
n.insertChild(numParams, path, fullPath, handlers)
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// 更新当前节点的最大参数个数
if numParams > n.maxParams {
n.maxParams = numParams
}
// 找到最长的通用前缀
// 这也意味着公共前缀不包含“:”"或“*” /
// 因为现有键不能包含这些字符。
i := longestCommonPrefix(path, n.path)
// 分裂边缘(此处分裂的是当前树节点)
// 例如一开始path是search,新加入support,s是他们通用的最长前缀部分
// 那么会将s拿出来作为parent节点,增加earch和upport作为child节点
if i < len(n.path) {
child := node{
path: n.path[i:], // 公共前缀后的部分作为子节点
wildChild: n.wildChild,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1, //子节点优先级-1
fullPath: n.fullPath,
}
// Update maxParams (max of all children)
for _, v := range child.children {
if v.maxParams > child.maxParams {
child.maxParams = v.maxParams
}
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = string([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// 将新来的节点插入新的parent节点作为子节点
if i < len(path) {
path = path[i:]
if n.wildChild { // 如果是参数节点
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
// Update maxParams of the child node
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// 检查通配符是否匹配
if len(path) >= len(n.path) && n.path == path[:len(n.path)] {
// 检查更长的通配符, 例如 :name and :names
if len(n.path) >= len(path) || path[len(n.path)] == '/' {
continue walk
}
}
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(path, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
// 取path首字母,用来与indices做比较
c := path[0]
// 处理参数后加斜线情况
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// 检查路path下一个字节的子节点是否存在
// 比如s的子节点现在是earch和upport,indices为eu
// 如果新加一个路由为super,那么就是和upport有匹配的部分u,将继续分列现在的upport节点
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// 否则就插入
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
// 注意这里是直接拼接第一个字符到n.indices
n.indices += string([]byte{c})
child := &node{
maxParams: numParams,
fullPath: fullPath,
}
// 追加子节点
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
}
n.insertChild(numParams, path, fullPath, handlers)
return
}
// 已经注册过的节点
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
return
}
}
其实上面的代码很好理解,大家可以参照动画尝试将以下情形代入上面的代码逻辑,体味整个路由树构造的详细过程:
-
第一次注册路由,例如注册search
-
继续注册一条没有公共前缀的路由,例如blog
-
注册一条与先前注册的路由有公共前缀的路由,例如support

insertChild
// tree.go
func (n *node) insertChild(numParams uint8, path string, fullPath string, handlers HandlersChain) {
// 找到所有的参数
for numParams > 0 {
// 查找前缀直到第一个通配符
wildcard, i, valid := findWildcard(path)
if i < 0 { // 没有发现通配符
break
}
// 通配符的名称必须包含':' 和 '*'
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// 检查通配符是否有名称
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
// 检查这个节点是否有已经存在的子节点
// 如果我们在这里插入通配符,这些子节点将无法访问
if len(n.children) > 0 {
panic("wildcard segment '" + wildcard +
"' conflicts with existing children in path '" + fullPath + "'")
}
if wildcard[0] == ':' { // param
if i > 0 {
// 在当前通配符之前插入前缀
n.path = path[:i]
path = path[i:]
}
n.wildChild = true
child := &node{
nType: param,
path: wildcard,
maxParams: numParams,
fullPath: fullPath,
}
n.children = []*node{child}
n = child
n.priority++
numParams--
// 如果路径没有以通配符结束
// 那么将有另一个以'/'开始的非通配符子路径。
if len(wildcard) < len(path) {
path = path[len(wildcard):]
child := &node{
maxParams: numParams,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
n = child // 继续下一轮循环
continue
}
// 否则我们就完成了。将处理函数插入新叶子中
n.handlers = handlers
return
}
// catchAll
if i+len(wildcard) != len(path) || numParams > 1 {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
// currently fixed width 1 for '/'
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// 第一个节点:路径为空的catchAll节点
child := &node{
wildChild: true,
nType: catchAll,
maxParams: 1,
fullPath: fullPath,
}
// 更新父节点的maxParams
if n.maxParams < 1 {
n.maxParams = 1
}
n.children = []*node{child}
n.indices = string('/')
n = child
n.priority++
// 第二个节点:保存变量的节点
child = &node{
path: path[i:],
nType: catchAll,
maxParams: 1,
handlers: handlers,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
return
}
// 如果没有找到通配符,只需插入路径和句柄
n.path = path
n.handlers = handlers
n.fullPath = fullPath
}
insertChild函数是根据path本身进行分割,将/分开的部分分别作为节点保存,形成一棵树结构。参数匹配中的:和*的区别是,前者是匹配一个字段而后者是匹配后面所有的路径。
路由匹配
通过调用net/http来启动服务,由于engine实现了ServeHTTP方法,只需要直接传engine对象就可以完成初始化并启动,我们先来看gin框架处理请求的入口函数ServeHTTP:
g.Run()
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine)
return
}
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
//来自 net/http 定义的接口,只要实现了这个接口就可以作为处理请求的函数,上面传入的engine实现了Handler方法,所以后面调用这个方法的时候使用下面的进行操作
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
//实现了ServeHTTP方法
// gin.go
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 这里使用了对象池
c := engine.pool.Get().(*Context)
// 这里有一个细节就是Get对象后做初始化
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c) // 我们要找的处理HTTP请求的函数
engine.pool.Put(c) // 处理完请求后将对象放回池子
}
函数很长,这里省略了部分代码,只保留相关逻辑代码:
// gin.go
func (engine *Engine) handleHTTPRequest(c *Context) {
// ...
// 根据请求方法找到对应的路由树
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// 在路由树中根据path查找
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // 执行函数链条
c.writermem.WriteHeaderNow()
return
}
// ...
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
路由匹配是由节点的 getValue方法实现的。getValue根据给定的路径(键)返回nodeValue值,保存注册的处理函数和匹配到的路径参数数据。
如果找不到任何处理函数,则会尝试TSR(尾随斜杠重定向)。
代码虽然很长,但还算比较工整。大家可以借助注释看一下路由查找及参数匹配的逻辑。
// tree.gotype nodeValue struct {
handlers HandlersChain
params Params // []Param
tsr bool
fullPath string}// ...func (n *node) getValue(path string, po Params, unescape bool) (value nodeValue) {
value.params = po
walk: // Outer loop for walking the tree
for {
prefix := n.path if path == prefix {
// 我们应该已经到达包含处理函数的节点。
// 检查该节点是否注册有处理函数
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath return
}
if path == "/" && n.wildChild && n.nType != root {
value.tsr = true
return
}
// 没有找到处理函数 检查这个路径末尾+/ 是否存在注册函数
indices := n.indices for i, max := 0, len(indices); i < max; i++ {
if indices[i] == '/' {
n = n.children[i]
value.tsr = (len(n.path) == 1 && n.handlers != nil) ||
(n.nType == catchAll && n.children[0].handlers != nil)
return
}
}
return
}
if len(path) > len(prefix) && path[:len(prefix)] == prefix {
path = path[len(prefix):]
// 如果该节点没有通配符(param或catchAll)子节点
// 我们可以继续查找下一个子节点
if !n.wildChild {
c := path[0]
indices := n.indices for i, max := 0, len(indices); i < max; i++ {
if c == indices[i] {
n = n.children[i] // 遍历树
continue walk }
}
// 没找到
// 如果存在一个相同的URL但没有末尾/的叶子节点
// 我们可以建议重定向到那里
value.tsr = path == "/" && n.handlers != nil
return
}
// 根据节点类型处理通配符子节点
n = n.children[0]
switch n.nType {
case param:
// find param end (either '/' or path end)
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// 保存通配符的值
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // 在预先分配的容量内扩展slice
value.params[i].Key = n.path[1:]
val := path[:end]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(val); err != nil {
value.params[i].Value = val // fallback, in case of error
}
} else {
value.params[i].Value = val }
// 继续向下查询
if end < len(path) {
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk }
// ... but we can't
value.tsr = len(path) == end+1
return
}
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath return
}
if len(n.children) == 1 {
// 没有找到处理函数. 检查此路径末尾加/的路由是否存在注册函数
// 用于 TSR 推荐
n = n.children[0]
value.tsr = n.path == "/" && n.handlers != nil
}
return
case catchAll:
// 保存通配符的值
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // 在预先分配的容量内扩展slice
value.params[i].Key = n.path[2:]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(path); err != nil {
value.params[i].Value = path // fallback, in case of error
}
} else {
value.params[i].Value = path }
value.handlers = n.handlers
value.fullPath = n.fullPath return
default:
panic("invalid node type")
}
}
// 找不到,如果存在一个在当前路径最后添加/的路由
// 我们会建议重定向到那里
value.tsr = (path == "/") ||
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' &&
path == prefix[:len(prefix)-1] && n.handlers != nil)
return
}}
gin框架中间件详解
gin框架涉及中间件相关有4个常用的方法,它们分别是c.Next()、c.Abort()、c.Set()、c.Get()。
中间件的注册
gin框架中的中间件设计很巧妙,我们可以首先从我们最常用的r := gin.Default()的Default函数开始看,它内部构造一个新的engine之后就通过Use()函数注册了Logger中间件和Recovery中间件:
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery()) // 默认注册的两个中间件
return engine
}
继续往下查看一下Use()函数的代码:
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
engine.RouterGroup.Use(middleware...) // 实际上还是调用的RouterGroup的Use函数
engine.rebuild404Handlers()
engine.rebuild405Handlers()
return engine
}
从下方的代码可以看出,注册中间件其实就是将中间件函数追加到group.Handlers中:
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {
group.Handlers = append(group.Handlers, middleware...)
return group.returnObj()
}
而我们注册路由时会将对应路由的函数和之前的中间件函数结合到一起:
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers) // 将处理请求的函数与中间件函数结合
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
其中结合操作的函数内容如下,注意观察这里是如何实现拼接两个切片得到一个新切片的。
const abortIndex int8 = math.MaxInt8 / 2
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
if finalSize >= int(abortIndex) { // 这里有一个最大限制
panic("too many handlers")
}
mergedHandlers := make(HandlersChain, finalSize)
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}
也就是说,我们会将一个路由的中间件函数和处理函数结合到一起组成一条处理函数链条HandlersChain,而它本质上就是一个由HandlerFunc组成的切片:
type HandlersChain []HandlerFunc
中间件的执行
我们在上面路由匹配的时候见过如下逻辑:
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // 执行函数链条
c.writermem.WriteHeaderNow()
return
}
其中c.Next()就是很关键的一步,它的代码很简单:
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}
从上面的代码可以看到,这里通过索引遍历HandlersChain链条,从而实现依次调用该路由的每一个函数(中间件或处理请求的函数)。

我们可以在中间件函数中通过再次调用c.Next()实现嵌套调用(func1中调用func2;func2中调用func3),
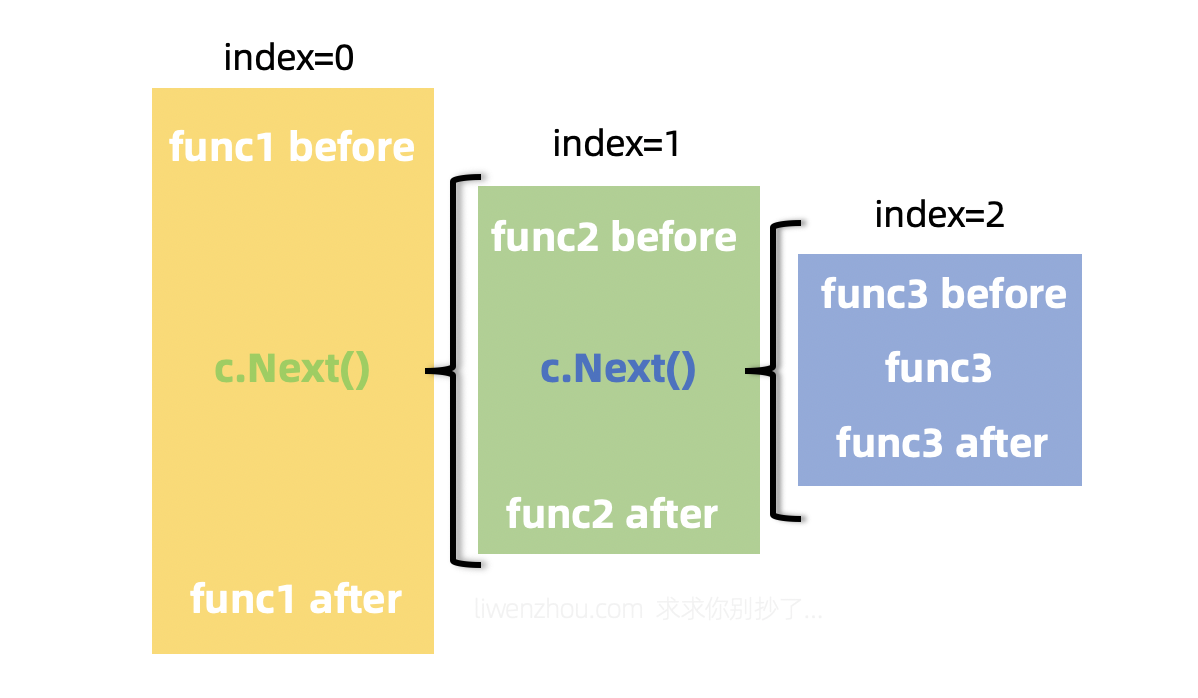
或者通过调用c.Abort()中断整个调用链条,从当前函数返回。
func (c *Context) Abort() {
c.index = abortIndex // 直接将索引置为最大限制值,从而退出循环
}
c.Set()/c.Get()
c.Set()和c.Get()这两个方法多用于在多个函数之间通过c传递数据的,比如我们可以在认证中间件中获取当前请求的相关信息(userID等)通过c.Set()存入c,然后在后续处理业务逻辑的函数中通过c.Get()来获取当前请求的用户。c就像是一根绳子,将该次请求相关的所有的函数都串起来了。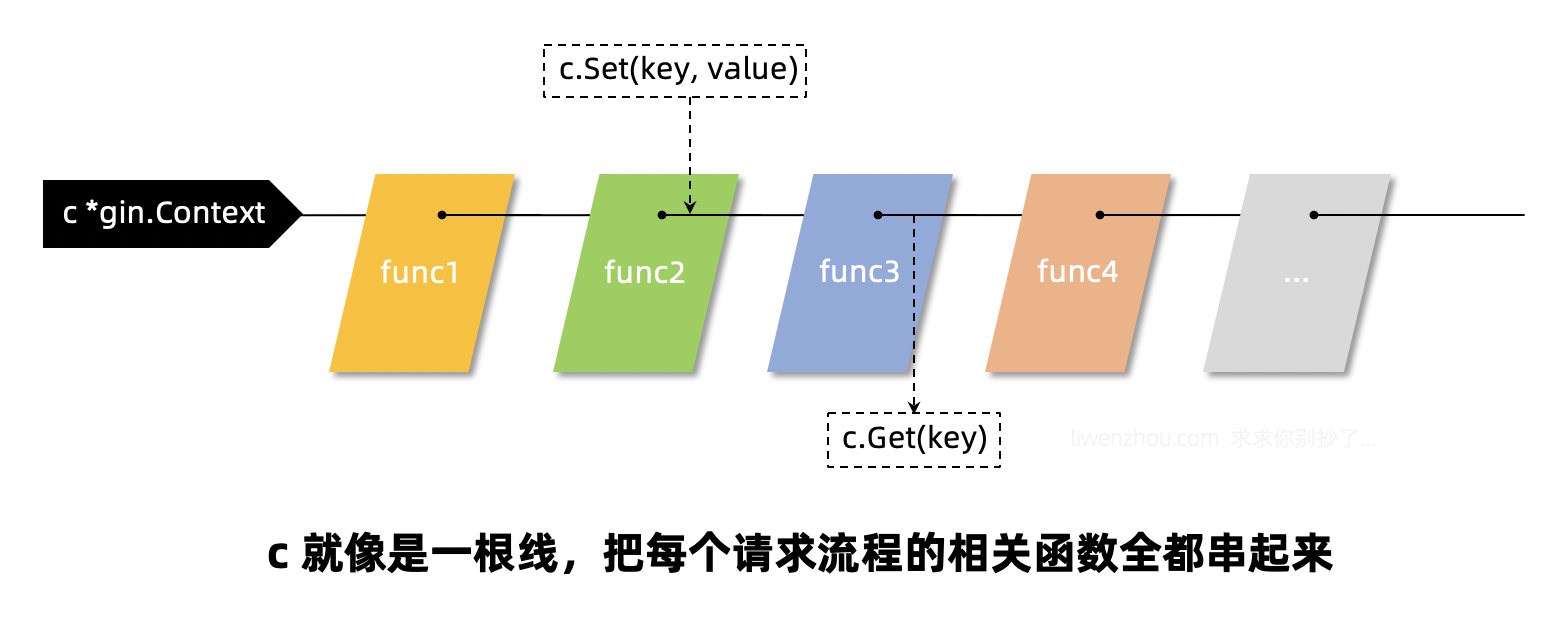
总结
-
gin框架路由使用前缀树,路由注册的过程是构造前缀树的过程,路由匹配的过程就是查找前缀树的过程。
-
gin框架的中间件函数和处理函数是以切片形式的调用链条存在的,我们可以顺序调用也可以借助
c.Next()方法实现嵌套调用。 -
借助
c.Set()和c.Get()方法我们能够在不同的中间件函数中传递数据。
–
参考:https://www.liwenzhou.com/posts/Go/read_gin_sourcecode/
–
–
评论前必须登录!
注册