 江哥架构师笔记
江哥架构师笔记cap理论,base理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
BASE强调牺牲高一致性,从而获得可用性,数据允许在一段时间内的不一致,只要保证最终一致就可以
常见的场景:
-
分布式锁:redis实现,etcd实现
-
数据库主从复制:全同步复制,半同步复制,异步复制
-
数据库隔离级别:读未提交,读已提交,可重复读,串行化

一致性的分类
-
强一致性
-
说明:保证系统改变提交以后立即改变集群的状态。
-
模型:
-
Paxos
-
Raft(muti-paxos)
-
ZAB(muti-paxos)
-
弱一致性
-
说明:也叫最终一致性,系统不保证改变提交以后立即改变集群的状态,但是随着时间的推移最终状态是一致的。
-
模型:
-
DNS系统
一致性算法实现举例
-
Google的Chubby分布式锁服务,采用了Paxos算法
-
etcd分布式键值数据库,采用了Raft算法
-
ZooKeeper分布式应用协调服务,Chubby的开源实现,采用ZAB算法
etcd写请求执行流程

Raft将分布式一致性问题分为Leader选举和Log复制
raft协议中的leader选举
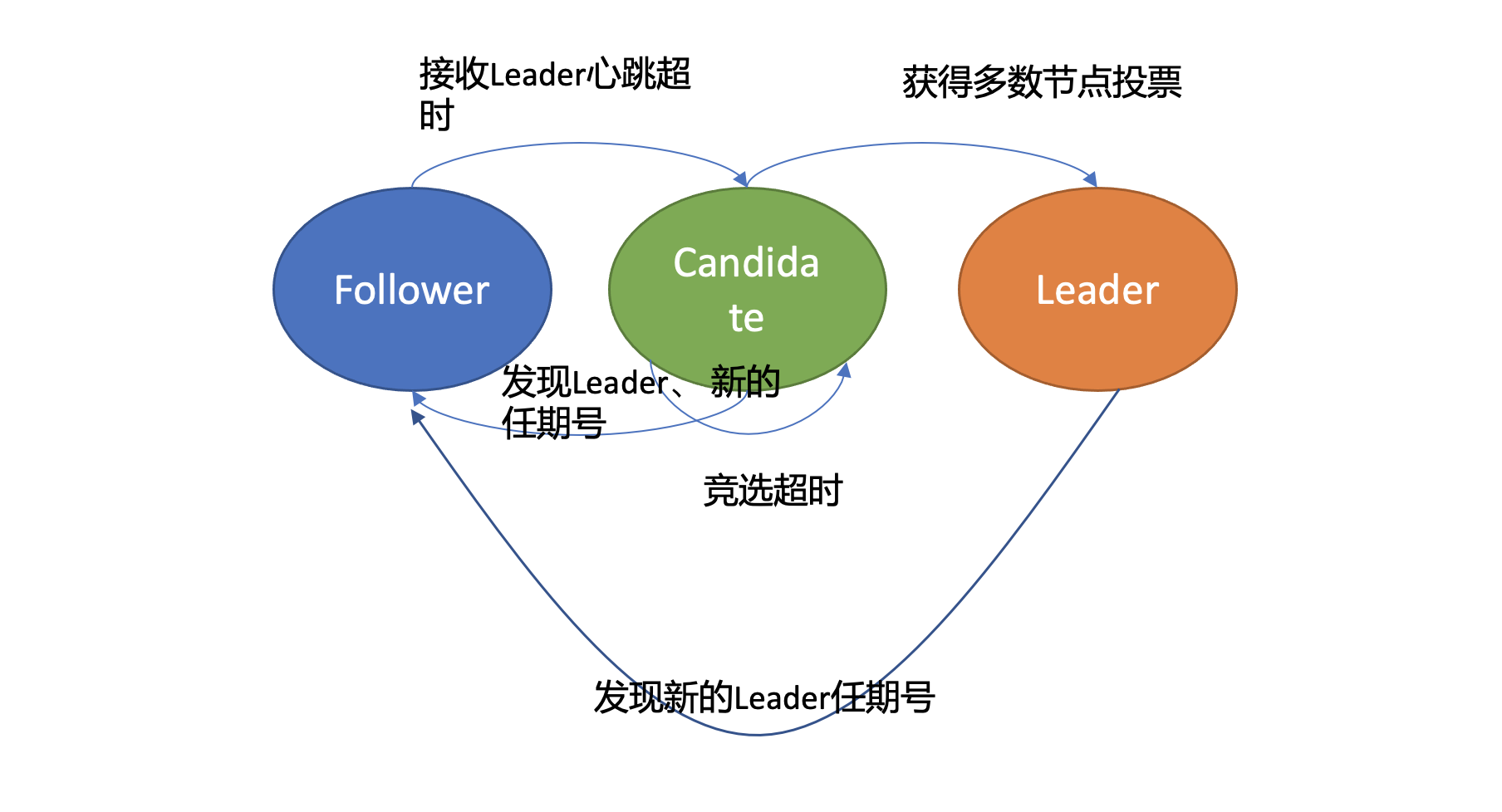
首先在 Raft 协议中它定义了集群中的如下节点状态,任何时刻,每个节点肯定处于其中一个状态:
-
Follower,跟随者, 同步从 Leader 收到的日志,etcd 启动的时候默认为此状态;
-
Candidate,竞选者,可以发起 Leader 选举;
-
Leader,集群领导者, 唯一性,拥有同步日志的特权,需定时广播心跳给 Follower 节点,以维持领导者身份。
假设集群总共 3 个节点,A 节点为 Leader,B、C 节点为 Follower。
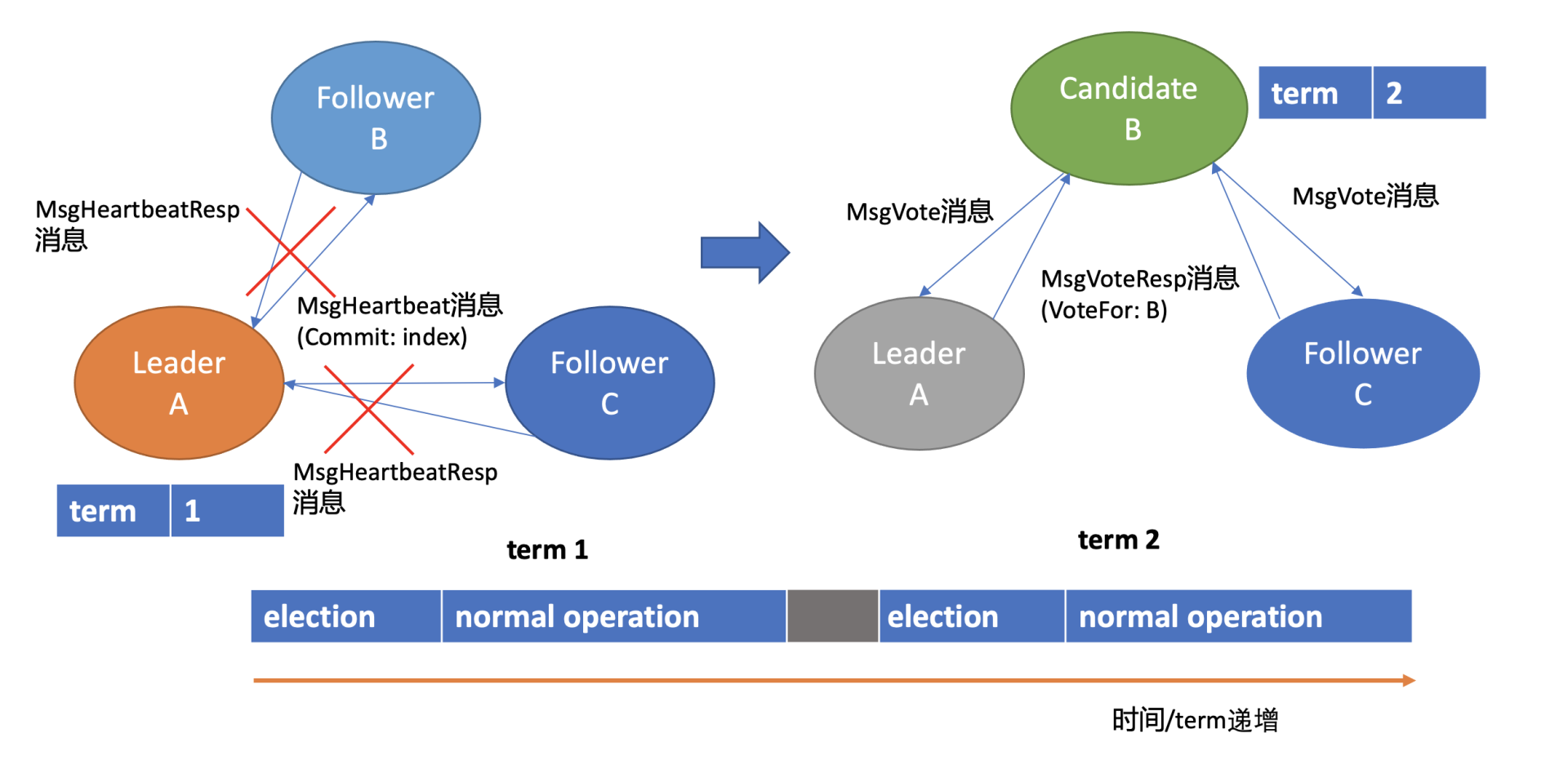
收到竞选消息后投票的依据:
-
C 节点判断 B 节点的数据至少和自己一样新
-
B 节点任期号大于 C 当前任期号
-
并且 C 未投票给其他候选者
当宕机节点恢复,A 节点的数据是远远落后 B、C 的,是无法获得集群 Leader 地位的,发起的选举无效且对集群稳定性有伤害。
为解决此问题,Follower 在转换成 Candidate 状态前,先进入 PreCandidate 状态,不自增任期号, 发起预投票。若获得集群多数节点认可,确定有概率成为 Leader 才能进入 Candidate 状态,发起选举流程

raft协议中日志复制流程
Leader 收到 put 请求后,向 Follower 节点复制日志的整体流程图
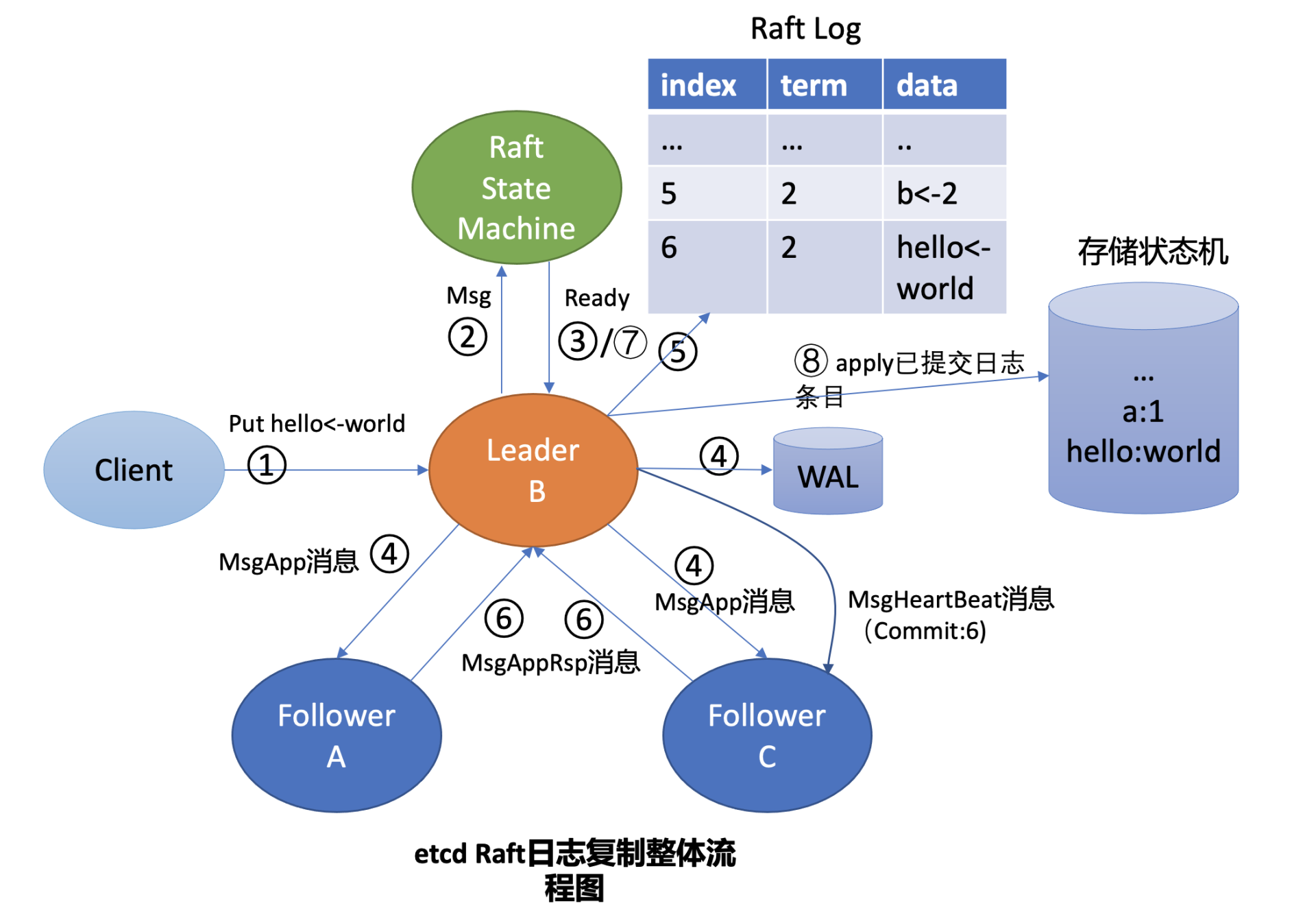
Leader 会维护两个核心字段来追踪各个 Follower 的进度信息:
-
一个字段是 NextIndex, 它表示 Leader 发送给 Follower 节点的下一个日志条目索引
-
一个字段是 MatchIndex, 它表示 Follower 节点已复制的最大日志条目的索引
etcdserver 模块通过 channel 从 Raft 模块获取到 Ready 结构后(流程图中的序号 3 流程),因 B 节点是 Leader,它首先会通过基于 HTTP 协议的网络模块将追加日志条目消息(MsgApp)广播给 Follower,并同时将待持久化的日志条目持久化到 WAL 文件中(流程图中的序号 4 流程),最后将日志条目追加到稳定的 Raft 日志存储中(流程图中的序号 5 流程)。
各个 Follower 收到追加日志条目(MsgApp)消息,并通过安全检查后,它会持久化消息到 WAL 日志中,并将消息追加到 Raft 日志存储,随后会向 Leader 回复一个应答追加日志条目(MsgAppResp)的消息,告知 Leader 当前已复制的日志最大索引(流程图中的序号 6 流程)。
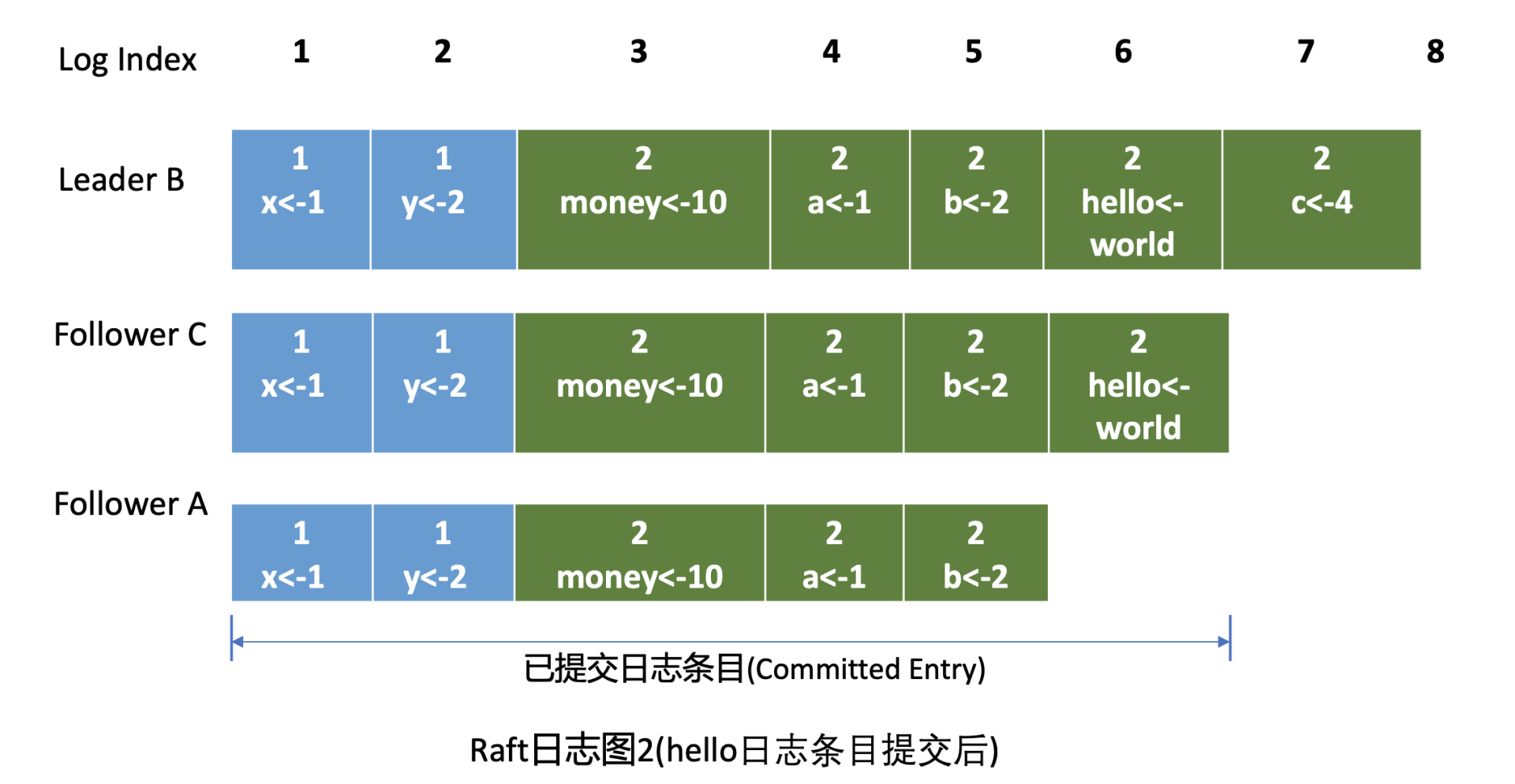
Leader 收到应答追加日志条目(MsgAppResp)消息后,会将 Follower 回复的已复制日志最大索引更新到跟踪 Follower 进展的 Match Index 字段,如下面的日志图 2 中的 Follower C MatchIndex 为 6,Follower A 为 5,日志图 2 描述的是 hello 日志条目提交后的各节点 Raft 日志状态。

备注:
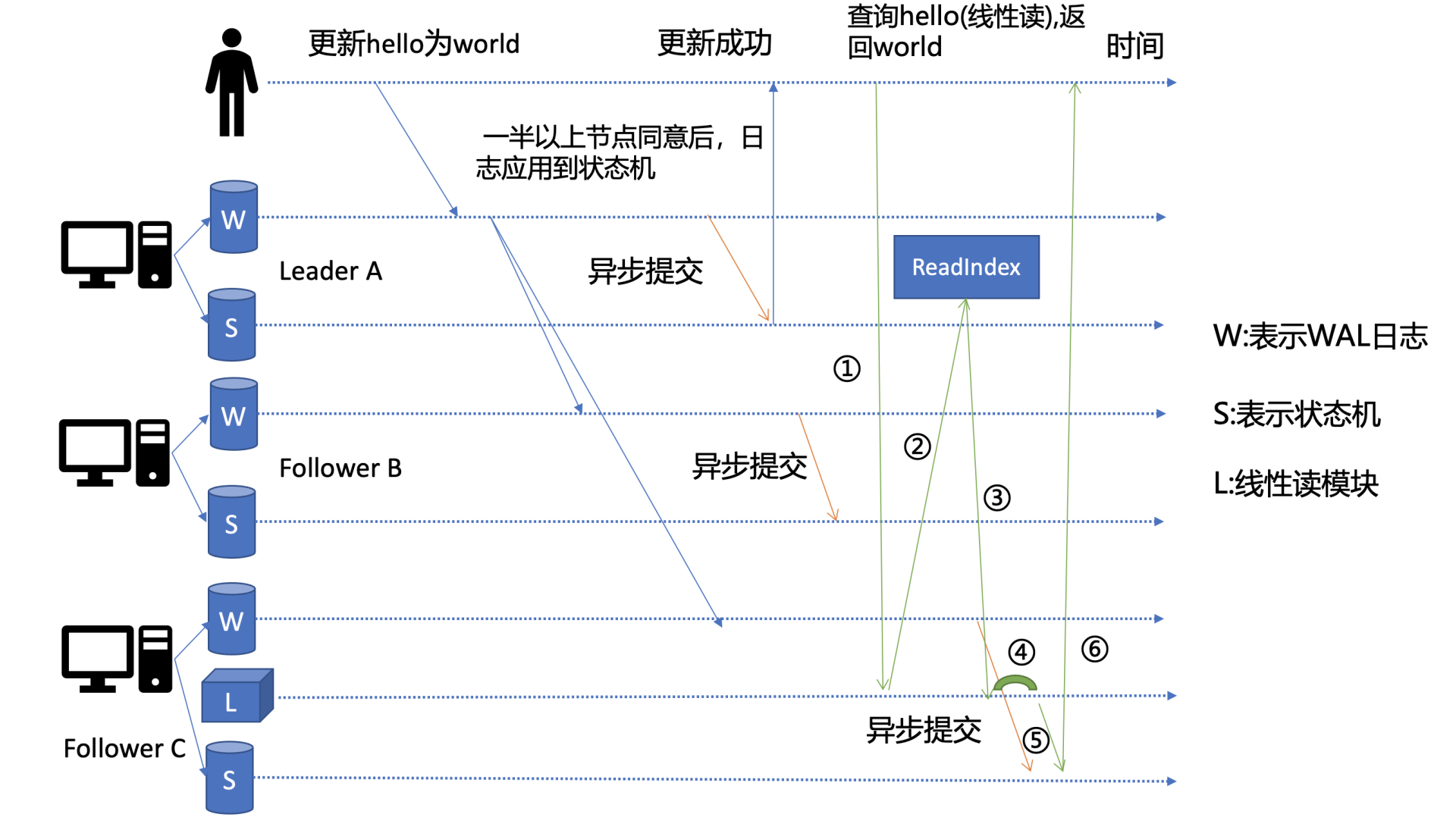
只有leader可以进行写操作。每个节点都可以进行读,为了保证数据一致性,引入了readindex机制
分布式一致性需要程序自身保证,或者业务引入开源的sdk来实现。容器化只是改变服务的部署方式
问题
问题1:当出现网络分区的时候,选举和日志复制会不会有问题?

问题2:如果一个日志完整度相对较高的节点因为自己随机时间比其他节点的长,没能最先发起竞选,其他节点当上leader后同步自己的日志岂不是冲突了?
这个日志完整度相对较高的节点,投票时有竞选规则安全限制,如果它的节点比较新会拒绝投票,至于最终先发起选举的节点能否赢得选举,要看其他节点数据情况,如果多数节点的数据比它新,那么先发起选举的节点就无法获得多数选票,如果5个节点中,只有一个节点数据比较长,那的确会被覆盖,但是这是安全的,说明这个数据并未被集群节点多数确认
问题3:如果leader将消息同步到大多数节点后,返回给客户端途中,leader宕机,客户端没有收到消息怎么办?
需要靠客户端实现幂等,通过业务唯一id等
问题4:哪些场景会出现 Follower 日志与 Leader 冲突?
etcd特别依赖磁盘I/O性能,日志条目需要同步持久化到磁盘,当心跳间隔是100ms,选举超时是1s, 如果fsync 日志条目WAL耗时不稳定、波动很大、超过1秒,那集群就会频繁选举。
https://www.cnblogs.com/gaorong/p/7274681.html
问题5:follower如何删除无效日志?
leader 处理不一致是通过强制 follower 直接复制自己的日志来解决。因此在 follower 中的冲突的日志条目会被 leader 的日志覆盖。leader 会记录 follower 的日志复制进度 nextIndex,如果 follower 在追加日志时一致性检查失败,就会拒绝请求,此时 leader 就会减小 nextIndex 值并进行重试,最终在某个位置让 follower 跟 leader 一致。
这里我补充下为什么 WAL 日志模块只通过追加,也能删除已持久化冲突的日志条目呢? 其实这里 etcd 在实现上采用了一些比较有技巧的方法,在 WAL 日志中的确没删除废弃的日志条目,你可以在其中搜索到冲突的日志条目。只是 etcd 加载 WAL 日志时,发现一个 raft log index 位置上有多个日志条目的时候,会通过覆盖的方式,将最后写入的日志条目追加到 raft log 中,实现了删除冲突日志条目效果,
问题6:在数据敏感度要求比较高的场景,如果主写入一个key,并且同步到大多数节点。节点c因为磁盘io压力大,没有及时把wal日志里数据同步到snapshot里,会不会出现读不一致?
串行读:直接读状态机数据返回、无需通过 Raft 协议与集群进行交互的模式,在 etcd 里叫做串行 (Serializable) 读,它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
线性读之readindex:一旦一个值更新成功,随后任何通过线性读的 client 都能及时访问到。虽然集群中有多个节点,但 client 通过线性读就如访问一个节点一样。etcd 默认读模式是线性读,因为它需要经过 Raft 协议模块,反应的是集群共识,因此在延时和吞吐量上相比串行读略差一点,适用于对数据一致性要求高的场景
raft动图演示:http://kailing.pub/raft/index.html